Last month, Julia 1.0 was released– hooray! I installed it on my Ubuntu 18.04 machine with
cd ~/Downloads
gpg --import juliareleases.asc
gpg --verify julia-1.0.0-linux-x86_64.tar.gz.asc
cd ~/julia
tar xf ~/Downloads/julia-1.0.0-linux-x86_64.tar.gz
cd ~/bin
ln -s ../julia/julia-1.0.0/bin/julia
That last part linked it to by bin directory, which is already in my path.
$ which julia
/home/tim/bin/julia
$ julia --version
julia version 1.0.0
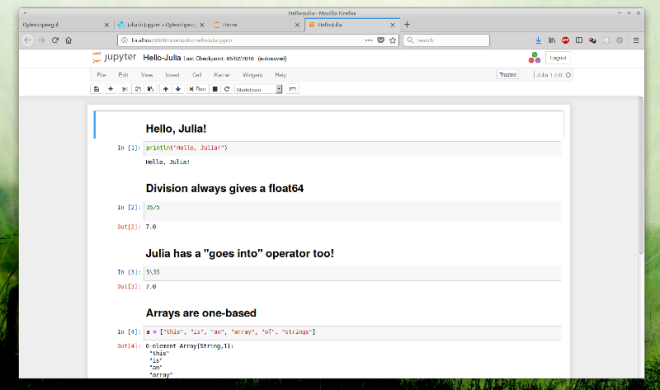
Today, I tried to use Julia from a Jupyter notebook. Jupyter is already installed.
$ which jupyter
/usr/bin/jupyter
$ jupyter --version
4.4.0
I installed it last year with
sudo apt install jupyter-core jupyter-notebook
This has been working fine and I have notebooks in Python 2, Python 3, Perl 5, Perl 6, and Clojure. However, Julia didn’t like it.
$ julia
julia> using Pkg
julia> Pkg.add("IJulia")
...
julia> using IJulia
[ Info: Precompiling IJulia [7073ff75-c697-5162-941a-fcdaad2a7d2a]
ERROR: LoadError: IJulia not properly installed. Please run Pkg.build("IJulia")
Stacktrace:
...
Running Pkg.build and a little bit of googling revealed that I didn’t have a jupyter-kernelspec command. Why not?
$ jupyter-kernelspec
Command 'jupyter-kernelspec' not found, but can be installed with:
sudo apt install jupyter-client
Ah. I hadn’t installed jupyter-client, just jupyter-core and jupyter-notebook. Running that command and then rebuilding IJulia worked a treat. Now, either
julia> using IJulia
julia> notebook()
from the Julia prompt, or
$ jupyter notebook
from the shell prompt starts up Jupyter (and Julia 1.0 is now on the list of kernels from which to choose). I prefer the latter, since I change to my Jupyter directory first, which shows all of my notebooks. Starting it within Julia shows my entire home directory.
Anyway, the bottom line is that the Julia 1.0 executable seems to work great with the Jupyter provided by Ubuntu; we just have to install the client too!
sudo apt install jupyter-core jupyter-notebook jupyter-client